用飛槳+ DJL 實作人臉口罩辨識¶
在這個教學中我們將會展示利用 PaddleHub 下載預訓練好的 PaddlePaddle 模型並針對範例照片做人臉口罩辨識。這個範例總共會分成兩個步驟:
- 用臉部檢測模型識別圖片中的人臉(無論是否有戴口罩)
- 確認圖片中的臉是否有戴口罩
這兩個步驟會包含使用兩個 Paddle 模型,我們會在接下來的內容介紹兩個模型對應需要做的前後處理邏輯
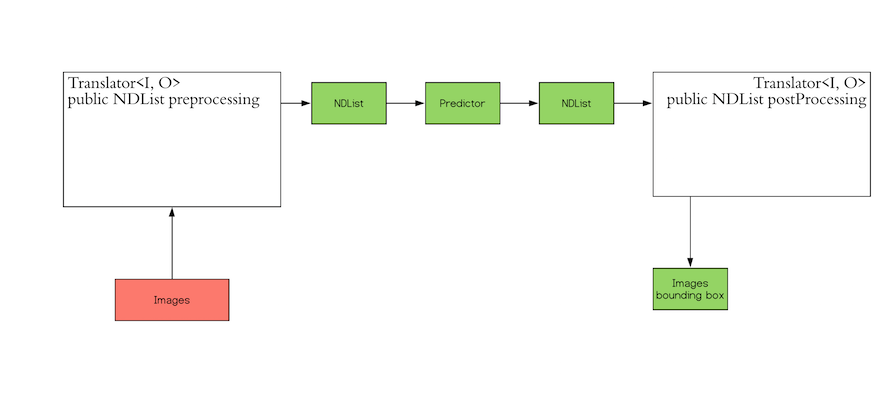
導入相關環境依賴及子類別¶
在這個例子中的前處理飛槳深度學習引擎需要搭配 DJL 混合模式進行深度學習推理,原因是引擎本身沒有包含 NDArray 操作,因此需要藉用其他引擎的 NDArray 操作能力來完成。這邊我們導入 PyTorch 來做協同的前處理工作:
// %mavenRepo snapshots https://oss.sonatype.org/content/repositories/snapshots/
%maven ai.djl:api:0.27.0
%maven ai.djl.paddlepaddle:paddlepaddle-model-zoo:0.27.0
%maven org.slf4j:slf4j-simple:1.7.36
// second engine to do preprocessing and postprocessing
%maven ai.djl.pytorch:pytorch-engine:0.27.0
import ai.djl.*;
import ai.djl.inference.*;
import ai.djl.modality.*;
import ai.djl.modality.cv.*;
import ai.djl.modality.cv.output.*;
import ai.djl.modality.cv.transform.*;
import ai.djl.modality.cv.translator.*;
import ai.djl.modality.cv.util.*;
import ai.djl.ndarray.*;
import ai.djl.ndarray.types.Shape;
import ai.djl.repository.zoo.*;
import ai.djl.translate.*;
import java.io.*;
import java.nio.file.*;
import java.util.*;
String url = "https://raw.githubusercontent.com/PaddlePaddle/PaddleHub/release/v1.5/demo/mask_detection/python/images/mask.jpg";
Image img = ImageFactory.getInstance().fromUrl(url);
img.getWrappedImage();

接著,讓我們試著對圖片做一些預處理的轉換:
NDList processImageInput(NDManager manager, Image input, float shrink) {
NDArray array = input.toNDArray(manager);
Shape shape = array.getShape();
array = NDImageUtils.resize(
array, (int) (shape.get(1) * shrink), (int) (shape.get(0) * shrink));
array = array.transpose(2, 0, 1).flip(0); // HWC -> CHW BGR -> RGB
NDArray mean = manager.create(new float[] {104f, 117f, 123f}, new Shape(3, 1, 1));
array = array.sub(mean).mul(0.007843f); // normalization
array = array.expandDims(0); // make batch dimension
return new NDList(array);
}
processImageInput(NDManager.newBaseManager(), img, 0.5f);
如上述所見,我們已經把圖片轉成如下尺寸的 NDArray: (披量, 通道(RGB), 高度, 寬度). 這是物件檢測模型輸入的格式
後處理¶
當我們做後處理時, 模型輸出的格式是 (number_of_boxes, (class_id, probability, xmin, ymin, xmax, ymax)). 我們可以將其存入預先建立好的 DJL 子類別 DetectedObjects 以便做後續操作. 我們假設有一組推論後的輸出是 ((1, 0.99, 0.2, 0.4, 0.5, 0.8)) 並且試著把人像框顯示在圖片上
DetectedObjects processImageOutput(NDList list, List<string> className, float threshold) {
NDArray result = list.singletonOrThrow();
float[] probabilities = result.get(":,1").toFloatArray();
List<string> names = new ArrayList<>();
List<double> prob = new ArrayList<>();
List<boundingbox> boxes = new ArrayList<>();
for (int i = 0; i < probabilities.length; i++) {
if (probabilities[i] >= threshold) {
float[] array = result.get(i).toFloatArray();
names.add(className.get((int) array[0]));
prob.add((double) probabilities[i]);
boxes.add(
new Rectangle(
array[2], array[3], array[4] - array[2], array[5] - array[3]));
}
}
return new DetectedObjects(names, prob, boxes);
}
NDArray tempOutput = NDManager.newBaseManager().create(new float[]{1f, 0.99f, 0.1f, 0.1f, 0.2f, 0.2f}, new Shape(1, 6));
DetectedObjects testBox = processImageOutput(new NDList(tempOutput), Arrays.asList("Not Face", "Face"), 0.7f);
Image newImage = img.duplicate();
newImage.drawBoundingBoxes(testBox);
newImage.getWrappedImage();

生成一個翻譯器並執行推理任務¶
透過這個步驟,你會理解 DJL 中的前後處理如何運作,現在讓我們把前數的幾個步驟串在一起並對真實圖片進行操作:
class FaceTranslator implements NoBatchifyTranslator<image, detectedobjects=""> {
private float shrink;
private float threshold;
private List<string> className;
FaceTranslator(float shrink, float threshold) {
this.shrink = shrink;
this.threshold = threshold;
className = Arrays.asList("Not Face", "Face");
}
@Override
public DetectedObjects processOutput(TranslatorContext ctx, NDList list) {
return processImageOutput(list, className, threshold);
}
@Override
public NDList processInput(TranslatorContext ctx, Image input) {
return processImageInput(ctx.getNDManager(), input, shrink);
}
}
要執行這個人臉檢測推理,我們必須先從 DJL 的 Paddle Model Zoo 讀取模型,在讀取模型之前我們必須指定好 Crieteria . Crieteria 是用來確認要從哪邊讀取模型而後執行 Translator 來進行模型導入. 接著,我們只要利用 Predictor 就可以開始進行推論
Criteria<image, detectedobjects=""> criteria = Criteria.builder()
.setTypes(Image.class, DetectedObjects.class)
.optModelUrls("djl://ai.djl.paddlepaddle/face_detection/0.0.1/mask_detection")
.optFilter("flavor", "server")
.optTranslator(new FaceTranslator(0.5f, 0.7f))
.build();
var model = criteria.loadModel();
var predictor = model.newPredictor();
DetectedObjects inferenceResult = predictor.predict(img);
newImage = img.duplicate();
newImage.drawBoundingBoxes(inferenceResult);
newImage.getWrappedImage();

int[] extendSquare(
double xmin, double ymin, double width, double height, double percentage) {
double centerx = xmin + width / 2;
double centery = ymin + height / 2;
double maxDist = Math.max(width / 2, height / 2) * (1 + percentage);
return new int[] {
(int) (centerx - maxDist), (int) (centery - maxDist), (int) (2 * maxDist)
};
}
Image getSubImage(Image img, BoundingBox box) {
Rectangle rect = box.getBounds();
int width = img.getWidth();
int height = img.getHeight();
int[] squareBox =
extendSquare(
rect.getX() * width,
rect.getY() * height,
rect.getWidth() * width,
rect.getHeight() * height,
0.18);
return img.getSubImage(squareBox[0], squareBox[1], squareBox[2], squareBox[2]);
}
List<detectedobjects.detectedobject> faces = inferenceResult.items();
getSubImage(img, faces.get(2).getBoundingBox()).getWrappedImage();

事先準備 Translator 並讀取模型¶
在使用臉部檢測模型的時候,我們可以利用 DJL 預先建好的 ImageClassificationTranslator 並且加上一些轉換。這個 Translator 提供了一些基礎的圖片翻譯處理並且同時包含一些進階的標準化圖片處理。以這個例子來說, 我們不需要額外建立新的 Translator 而使用預先建立的就可以
var criteria = Criteria.builder()
.setTypes(Image.class, Classifications.class)
.optModelUrls("djl://ai.djl.paddlepaddle/mask_classification/0.0.1/mask_classification")
.optFilter("flavor", "server")
.optTranslator(
ImageClassificationTranslator.builder()
.addTransform(new Resize(128, 128))
.addTransform(new ToTensor()) // HWC -> CHW div(255)
.addTransform(
new Normalize(
new float[] {0.5f, 0.5f, 0.5f},
new float[] {1.0f, 1.0f, 1.0f}))
.addTransform(nd -> nd.flip(0)) // RGB -> GBR
.build())
.build();
var classifyModel = criteria.loadModel();
var classifier = classifyModel.newPredictor();
執行推論任務¶
最後,要完成一個口罩識別的任務,我們只需要將上述的步驟合在一起即可。我們先將圖片做裁剪後並對其做上述的推論操作,結束之後再生成一個新的分類子類別 DetectedObjects:
List<string> names = new ArrayList<>();
List<double> prob = new ArrayList<>();
List<boundingbox> rect = new ArrayList<>();
for (DetectedObjects.DetectedObject face : faces) {
Image subImg = getSubImage(img, face.getBoundingBox());
Classifications classifications = classifier.predict(subImg);
names.add(classifications.best().getClassName());
prob.add(face.getProbability());
rect.add(face.getBoundingBox());
}
newImage = img.duplicate();
newImage.drawBoundingBoxes(new DetectedObjects(names, prob, rect));
newImage.getWrappedImage();
