LMI running Engines¶
In LMI, we offer two different running modes to operate the backend engine:
- Distributed Environment (MPI): Used to operate on single machine multi-gpu or multiple machines multi-gpu use cases
- Standard Python process (Python): Start a standalone python process to run the engine
You specify this operating mode through the option.mpi_mode=<true|false> configuration.
The operating modes for the built-in inference engines are described below.
- TensorRT-LLM (MPI): Use multiple MPI processes to run the backends
- vLLM (Python): vLLM internally will use Ray to spin up multiple processes
- HuggingFace Accelerate (Python): HF Accelerate internally managed the process workflow
In the next section, we will introduce a detailed breakdown on how we run those backends.
Python Engine operating in LMI (DJLServing)¶

In Python operating mode, LMI launches Python processes based on scanning
the system environment and number of Accelerators (GPU) for each process through CUDA_VISIBLE_DEVICES. During auto-scaling mode,
LMI manages Accelerators allocation and spins up processes with different Accelerators (GPU).
Under python Engine mode, LMI will establish socket connection and talk to the python process.
Enablement¶
You can use the following ways to enable Python Engine:
serving.properties
engine=Python
option.mpi_mode=false
Environment variables
OPTION_ENGINE=Python
OPTION_MPI_MODE=false
We use python mode by default as long as you specify option.model_id.
MPI Engine operating in LMI (DJLServing)¶
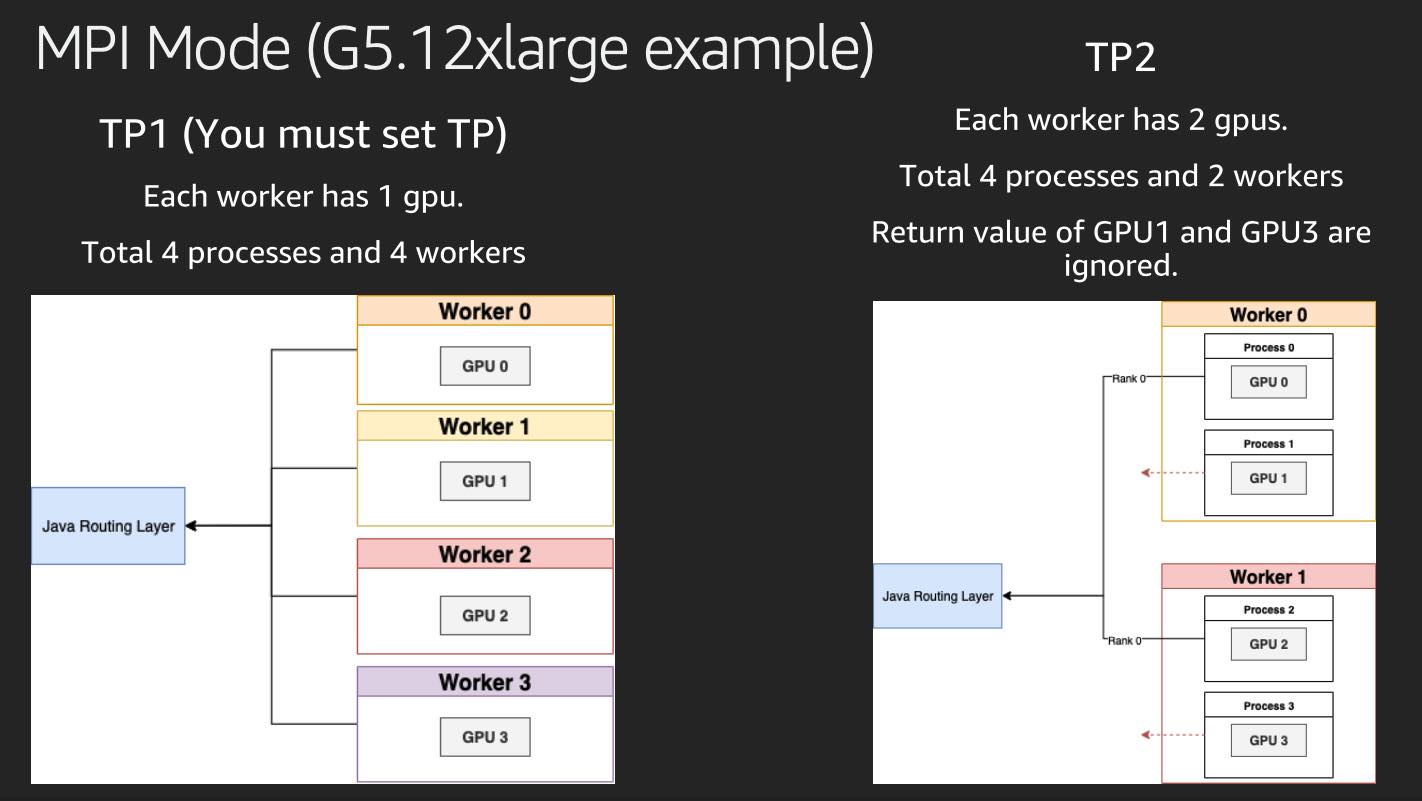
MPI in general means "Multi-Process-Interface". In LMI domain, you could also read as "Multi-Process-Inference".
DJLServing internally uses mpirun to spin up multiple processes depends on the setup.
The number of processes for LLM applications follows the tensor_parallel_degree configuration.
LMI establishes multiple socket connects to each process for communication and health check.
During each operation call (e.g. inference), LMI will send the same request to each process. At response back time,
LMI will just receive 1 result from rank 0 of the total processes.
MPI model also works well with LMI auto-scaling feature, user could specify multiple workers using different GPUs. LMI will spin up the corresponding copies in MPI environment.
Enablement¶
You can use the following ways to enable MPI Engine:
serving.properties
engine=Python
option.mpi_mode=true
Environment variable
OPTION_ENGINE=Python
OPTION_MPI_MODE=true