Memory Management¶
Memory is one of the biggest challenge in the area of deep learning, especially in Java. The greatest issue is that the garbage collector doesn't have control over the native memory. It doesn't know how much is used and how to free it. Beyond that, it can be too slow for high-memory usages such as training on a GPU.
Without the automatic memory management, it is still possible to manually free the memory. However, there are too many NDArrays that are created for such a thing to be practical.
For this reason, DJL uses the NDManager.
The NDManager behaves as both a factory and a scope.
All arrays created by a manager are part of its scope.
By freeing the manager, it can then free all the arrays attached to it.
This also includes arrays produced by operations such as NDArray.add(other) or Activation.relu(array).
They are attached to the manager of the input argument.
If it takes multiple NDArray inputs, it is attached to the manager for the first one.
It is also common to have a hierarchy of NDManagers. Each of them represent a different level of abstraction and point at which the data are freed. As an example, let's look at some common usages:
Inference Use Case¶
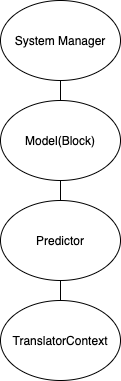
The structure of the NDManager for the classic inference case is like:
 .
.
At the top of the hierarchy is the system manager.
It contains memory which is global, and the system manager can't be closed.
When you create a new manager by calling NDManager.newBaseManager(), it is created as a child of the system manager.
Under the system manager, there is the manager for the model and then the predictor. Those are both likely to be long-lasting and contain the parameters to run prediction. The model would contain the standard copy and the predictor may contain additional copies of the parameters depending on the engine and wheter multiple devices are used.
Each time data is passed into a call to predict(), it is added to a PredictorContext manager.
This data is temporary and only lasts as long as the call to predict.
It ensures that all the temporary arrays created during the predict() call are promptly freed.
As long as the input and output to the Translator for the predictor are standard Java classes and not resources like NDArray or NDList, this will handle the memory automatically.
If instead an NDResource is used for either an input or output, the user must make sure that the memory is attached to a specific manager and freed when no longer needed.
Make sure that within the preprocessing, post-processing, and model, data is created only within the PredictorContext.
Memory created in other managers (especially the model or predictor) would not be freed and would constitute a memory leak.
Training Use Case¶
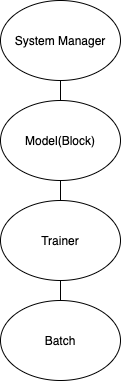
The structure of the NDManager for the classic training case is like:
 .
.
Like the inference use case, it contains the same system manager and model.
The Trainer behaves similarly to the Predictor, although only one Trainer should be created rather than one per device.
Then, there is also the Batch.
It contains memory which should be used for a training step, and freed directly afterwards.
Here, the use of the NDManager makes it possible to take up the whole GPU for each batch without straining the GC.
Note that a Batch must be manually closed at the end of the training step.
Make sure that within the training steps, loss, and model, data is created only within the Batch manager.
Memory created in other managers (especially the model or trainer) would not be freed and would constitute a memory leak.
If you remember to close the Batch and memory is still growing during the training step, some memory is likely being attached to the wrong manager.
Rules of Thumb:¶
- The output of an NDArray operation should be attached to the same manager as the input NDArray. The order matters as we use first NDArray's manager on the NDArray operation by default.
- If an intermediate NDArray gets into an upper level NDManager (e.g. from Trainer -> Model), this is a memory leak
- You can use
NDManager.debugDump()to see if any of NDManager's resource count is keep increasing. - If a large amount of intermediate NDArrays are needed, it is recommended to create your own subNDManager or close them manually.
Advanced Memory Management¶
There are also a few tools for more sophisticated memory management.
The first is by using ndManager.tempAttachAll().
This will allow a manager to "borrow" some resources (NDManager or NDList) from another manager.
When the borrower is closed, the resources are returned to the original manager.
The most common usage of temp attach is to create a scope for performing some computations.
A dedicated manager is created for the computation and the inputs are temporarily attached to it.
After the result is computed, the result is attached to a higher manager either manually or by using computationManager.ret(resource).
Then, the computation manager is closed which frees all intermediate computation memory and returns the input arrays back to their original manager.
Troubleshooting¶
If you find your memory increasing, here are some things to look for.
If you are doing training, make sure that you close the Batch.
If you are doing inference, make sure that the translator either uses standard Java classes (not NDManager or NDList) or that the prediction input/output are freed manually.
If none of these are the problem, one test is to try calling ndManager.cap().
Calling cap will block a manager from having additional data attached to it.
Try to cap the manager for the Model and/or the Trainer/Predictor before a training batch or prediction call.
This will throw an exception if any memory is attached to these higher managers accidentally.
You can also use BaseNDManager.debugDump(...) to help see what managers and resources are attached to a given manager.
Calling it on a manager repeatedly will let you know if the resource count is increasing.
It may also help to set names for the arrays or managers to help identify them within the dump.