AWS EMR DJL demo¶
This is a simple demo of DJL with Apache Spark on AWS EMR. The demo runs dummy classification with a PyTorch model.
Step 1: Prepare your dataset on S3¶
To successfully run this example,you need to upload the model file and training dataset to a S3 location where it is accessible by the Apache Spark Cluster.
AWS CLI¶
aws s3 mb "s3://your-bucket-name"
aws s3 sync s3://djl-ai/resources/demo/pytorch/traced_resnet18/ s3://your-bucket-name/traced_resnet18/
Use AWS Console¶
You can also do this by creating bucket using AWS online console and upload the files
Step 2: Configure the EMR¶
In this step, we are trying to create an Apache Spark yarn cluster with 1 master node and 2 child nodes.
AWS CLI¶
Here is a sample setup with AWS EMR using AWS CLI.
The Apache Spark version we are using is 2.4.5.
You will also need to specify the key name that bring you the access to the EC2 instance.
aws emr create-cluster \
--name "Spark cluster" \
--release-label emr-5.30.1 \
--applications Name=Hadoop Name=Spark \
--ec2-attributes KeyName=myKey \
--instance-type c5.2xlarge \
--instance-count 3 \
--use-default-roles
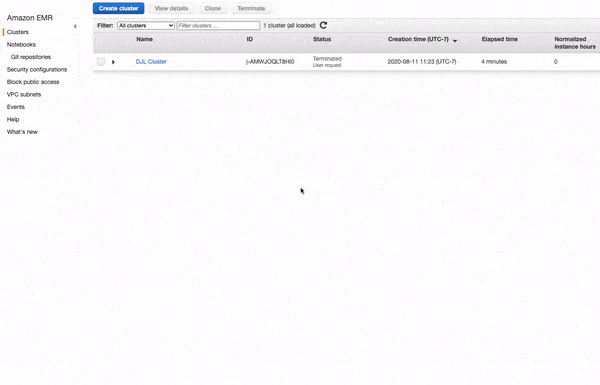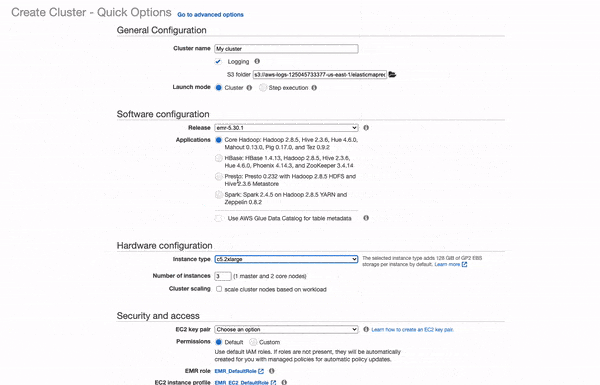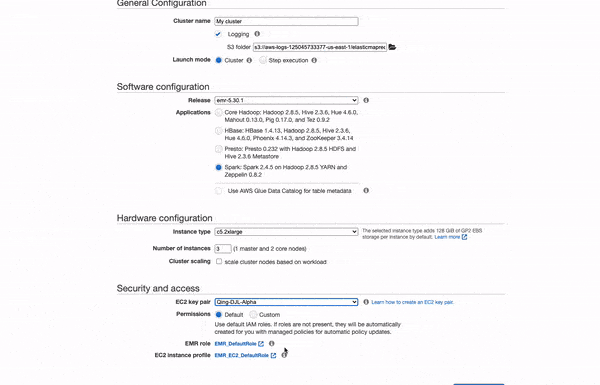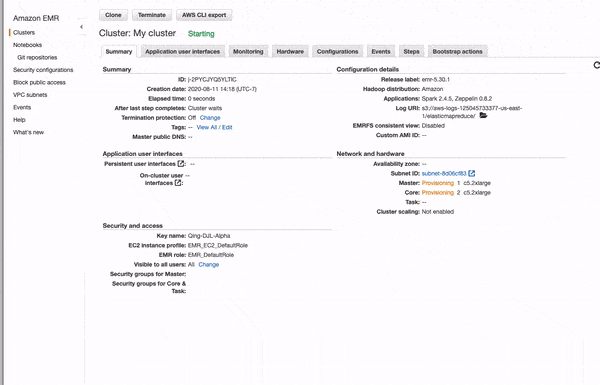
AWS Console¶
- Search "EMR" in AWS Console
- Click "Create Cluster"
- Select "Spark" in the "Software configuration"
- Pick an instance for Spark, we recommend have an instance with 4 GB memory as a minimum.
- Click "Create Cluster"
Step 3: Submit the Application and get the result¶
change the modelUrl in the DataProcessExample.scala to point to your S3 bucket.
After that, you can create a fat jar by doing the followings:
./gradlew shadowJar
This jar is located in build/libs and will be used to submit on Spark
You can upload this jar to your created S3 bucket.
Finally, you can submit this jar to spark to get the result. This can be done from the EMR interface or EMR master node through ssh.
ssh to master¶
You need to allow ssh in your security group by adding inbound rule SSH in your master security group to connect to master node.
aws s3 cp s3://your-bucket-name/AWSEMRDJL-1.0-SNAPSHOT.jar .
spark-submit AWSEMRDJL-1.0-SNAPSHOT.jar
After running, you can find result located in the hdfs result folder
$ hdfs dfs -ls result
-rw-r--r-- 1 hadoop hadoop 0 2020-08-12 18:23 result/_SUCCESS
-rw-r--r-- 1 hadoop hadoop 50000 2020-08-12 18:23 result/part-00000
-rw-r--r-- 1 hadoop hadoop 50000 2020-08-12 18:23 result/part-00001
Step 4: clean up¶
After running the project, please remember to terminate the cluster. You can simply do that from AWS console.
you can use the following sample code to clean up the bucket:
aws s3 rb --force s3://your-bucket-name
Learn more about DJL usage for Spark¶
For more information about an actual DJL image classification example on Apache Spark, please find here.