DJL Serving Architecture¶
DJL serving is built on top of Deep Java Library. You can visit the DJL github repository to learn more. For module, dependency and class overview refer to generated diagrams.
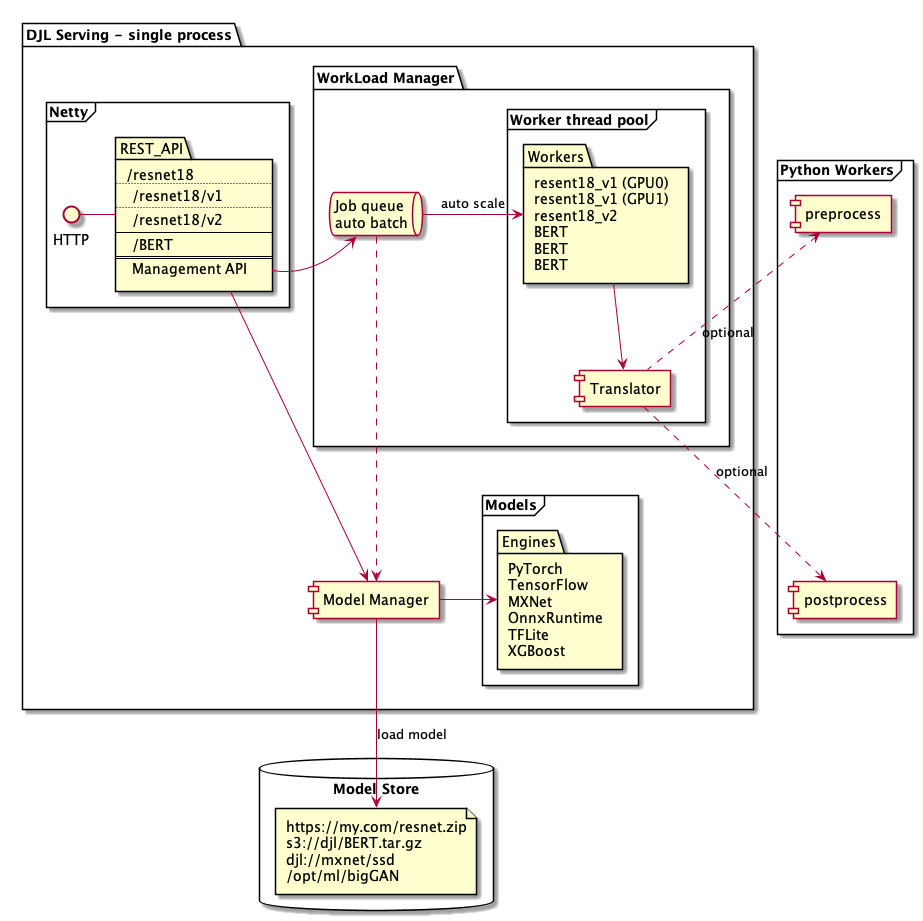
DJL Serving exists in roughly four layers:
- Frontend - A Netty HTTP client that accepts and manages incoming requests
- Workflows - A system for combining multiple models and glue code together into execution plans
- WorkLoadManager (WLM) - A worker thread management system supporting batching and routing.
There is also the model store, specified in the configuration, that specifies the models to be loaded on startup in the ModelManager.
Frontend¶
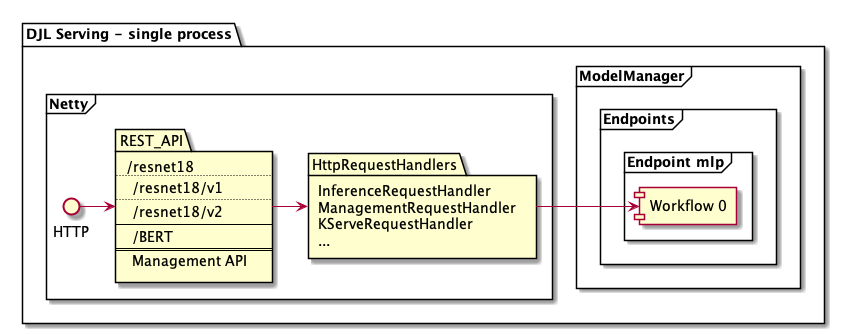
DJL Serving uses a Netty frontend to handle the incoming requests. It has a single Netty setup with multiple HttpRequestHandlers. Different request handlers will provide support for the inference API, Management API, or other APIs available from various plugins.
Those request handlers can then communicate with other layers of the DJL stack. Mainly, this is through the ModelManager which manages the various endpoints. Each endpoint can have multiple versions that each correspond to a Workflow. The inference API will call various workflows (assigned round-robin to the workflows in an endpoint). The management API can be used to CRUD the various endpoints and workflows in them.
Workflows¶
The workflow system is used to support various use cases involving multiple levels of models and glue code.
It is configured using a workflow.json file where you can describe the workflow pipeline and the models involved.
More details about workflows can be found in the workflows guide.
Within the workflow, the main purpose is to call various models. This is done through the WorkLoadManager. Creating and removing the workflow will add and remove the respective models from the WLM. The same model in multiple workflows will correspond to a single model in the WLM.
WorkLoadManager¶
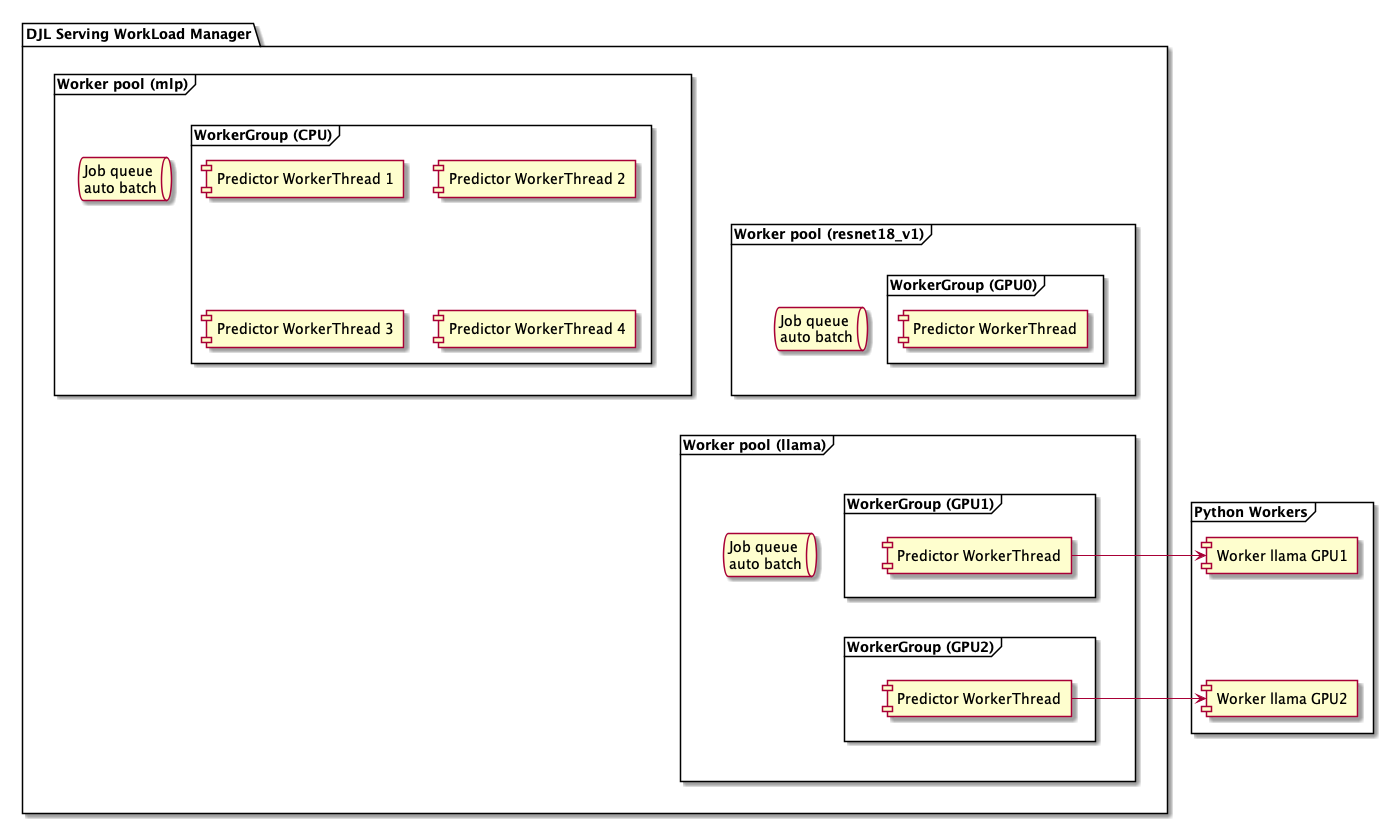
The backend is based around the WorkLoadManager module.
The WLM takes care of multiple worker threads for each model along with the batching and request routing to them.
It is also available separately and can be utilized through the WLM module (ai.djl.serving:wlm).
This may be useful if you want the DJL Serving worker scaling support, but not the HTTP frontend.
For each model, there is a worker pool corresponding to it's full support. Each worker pool has a job queue to manage the incoming requests. It also has a worker pool config describing the task (model) it runs.
The worker pool can then contain multiple worker groups. The groups correspond to the support for the model on a particular device. So, the same model can have worker groups for both CPU and GPU or on multiple GPUs by creating multiple worker groups.
Finally, each worker group can contain the individual worker threads. This allows for multiple threads on the same device (typically CPU) for the same model. The number of workers in a worker group can be automatically scaled with a minimum and maximum value. A constant number of workers can be set by having the same minimum and maximum workers.
Within each worker thread inside the WLM, there is a DJL Predictor. Depending on what Engine the Predictor is, it can run various models such as those from PyTorch, Tensorflow, XGBoost, or any of the other engines supported by DJL. Notably, there is also a Python Engine which can be used to run models, preprocessing, and postprocessing defined in a python script.
When using the Python engine, the DJL Python Predictor (PyPredictor) contains a python process. This means that each worker thread (in each worker group in each worker pool) has it's own process. The process can be used and closed through the PyPredictor.