Run this notebook online:![]()
Load your own MXNet BERT model¶
In the previous example, you run BERT inference with the model from Model Zoo. You can also load the model on your own pre-trained BERT and use custom classes as the input and output.
In general, the MXNet BERT model requires these three inputs:
- word indices: The index of each word in a sentence
- word types: The type index of the word.
- valid length: The actual length of the question and resource document tokens
We will dive deep into these details later.
There are dependencies we will use.
// %mavenRepo snapshots https://central.sonatype.com/repository/maven-snapshots/
%maven ai.djl:api:0.28.0
%maven ai.djl.mxnet:mxnet-engine:0.28.0
%maven ai.djl.mxnet:mxnet-model-zoo:0.28.0
%maven org.slf4j:slf4j-simple:1.7.36
Import java packages¶
import java.io.*;
import java.nio.file.*;
import java.util.*;
import java.util.stream.*;
import ai.djl.*;
import ai.djl.util.*;
import ai.djl.ndarray.*;
import ai.djl.ndarray.types.*;
import ai.djl.inference.*;
import ai.djl.translate.*;
import ai.djl.training.util.*;
import ai.djl.repository.zoo.*;
import ai.djl.modality.nlp.*;
import ai.djl.modality.nlp.qa.*;
import ai.djl.mxnet.zoo.nlp.qa.*;
import ai.djl.modality.nlp.bert.*;
import com.google.gson.annotations.SerializedName;
import java.nio.charset.StandardCharsets;
Reuse the previous input
var question = "When did BBC Japan start broadcasting?";
var resourceDocument = "BBC Japan was a general entertainment Channel.\n" +
"Which operated between December 2004 and April 2006.\n" +
"It ceased operations after its Japanese distributor folded.";
QAInput input = new QAInput(question, resourceDocument);
Dive deep into Translator¶
Inference in deep learning is the process of predicting the output for a given input based on a pre-defined model. DJL abstracts away the whole process for ease of use. It can load the model, perform inference on the input, and provide output. DJL also allows you to provide user-defined inputs. The workflow looks like the following:
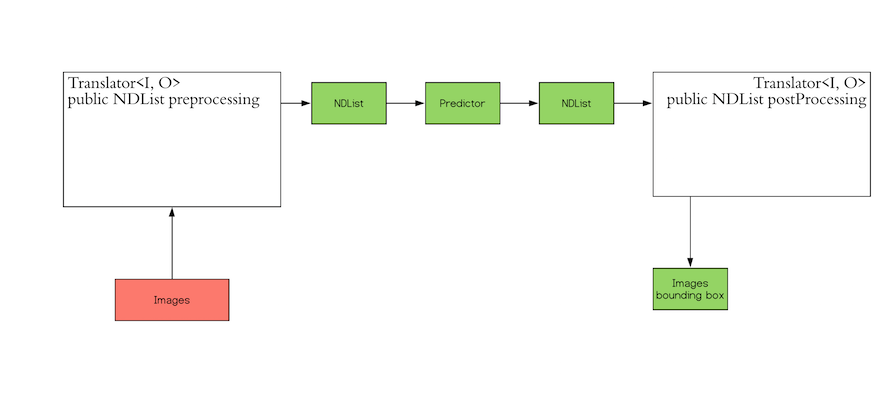
The red block ("Images") in the workflow is the input that DJL expects from you. The green block ("Images
bounding box") is the output that you expect. Because DJL does not know which input to expect and which output format that you prefer, DJL provides the Translator interface so you can define your own
input and output.
The Translator interface encompasses the two white blocks: Pre-processing and Post-processing. The pre-processing
component converts the user-defined input objects into an NDList, so that the Predictor in DJL can understand the
input and make its prediction. Similarly, the post-processing block receives an NDList as the output from the
Predictor. The post-processing block allows you to convert the output from the Predictor to the desired output
format.
Pre-processing¶
Now, you need to convert the sentences into tokens. We provide a powerful tool BertTokenizer that you can use to convert questions and answers into tokens, and batchify your sequence together. Once you have properly formatted tokens, you can use Vocabulary to map your token to BERT index.
The following code block demonstrates tokenizing the question and answer defined earlier into BERT-formatted tokens.
var tokenizer = new BertTokenizer();
List<string> tokenQ = tokenizer.tokenize(question.toLowerCase());
List<string> tokenA = tokenizer.tokenize(resourceDocument.toLowerCase());
System.out.println("Question Token: " + tokenQ);
System.out.println("Answer Token: " + tokenA);
BertTokenizer can also help you batchify questions and resource documents together by calling encode().
The output contains information that BERT ingests.
- getTokens: It returns a list of strings, including the question, resource document and special word to let the model tell which part is the question and which part is the resource document. Because MXNet BERT was trained with a fixed sequence length, you see the
[PAD]in the tokens as well. -
getTokenTypes: It returns a list of type indices of the word to indicate the location of the resource document. All Questions will be labelled with 0 and all resource documents will be labelled with 1.
[Question tokens...DocResourceTokens...padding tokens] => [000000...11111....0000]
-
getValidLength: It returns the actual length of the question and tokens, which are required by MXNet BERT.
-
getAttentionMask: It returns the mask for the model to indicate which part should be paid attention to and which part is the padding. It is required by PyTorch BERT.
[Question tokens...DocResourceTokens...padding tokens] => [111111...11111....0000]
MXNet BERT was trained with fixed sequence length 384, so we need to pass that in when we encode the question and resource doc.
BertToken token = tokenizer.encode(question.toLowerCase(), resourceDocument.toLowerCase(), 384);
System.out.println("Encoded tokens: " + token.getTokens());
System.out.println("Encoded token type: " + token.getTokenTypes());
System.out.println("Valid length: " + token.getValidLength());
Normally, words and sentences are represented as indices instead of tokens for training.
They typically work like a vector in a n-dimensional space. In this case, you need to map them into indices.
DJL provides Vocabulary to take care of you vocabulary mapping.
Assume your vocab.json is of the following format
{'token_to_idx':{'"slots": 19832,...}, 'idx_to_token':["[UNK]", "[PAD]", ...]}
We provide the vocab.json from our pre-trained BERT for demonstration.
DownloadUtils.download("https://djl-ai.s3.amazonaws.com/mlrepo/model/nlp/question_answer/ai/djl/mxnet/bertqa/vocab.json", "build/mxnet/bertqa/vocab.json", new ProgressBar());
class VocabParser {
@SerializedName("idx_to_token")
List<string> idx2token;
public static List<string> parseToken(URL file) {
try (InputStream is = file.openStream();
Reader reader = new InputStreamReader(is, StandardCharsets.UTF_8)) {
return JsonUtils.GSON.fromJson(reader, VocabParser.class).idx2token;
} catch (IOException e) {
throw new IllegalArgumentException("Invalid url: " + file, e);
}
}
}
URL url = Paths.get("build/mxnet/bertqa/vocab.json").toUri().toURL();
var vocabulary = DefaultVocabulary.builder()
.optMinFrequency(1)
.addFromCustomizedFile(url, VocabParser::parseToken)
.optUnknownToken("[UNK]")
.build();
You can easily convert the token to the index using vocabulary.getIndex(token) and the other way around using vocabulary.getToken(index).
long index = vocabulary.getIndex("car");
String token = vocabulary.getToken(2482);
System.out.println("The index of the car is " + index);
System.out.println("The token of the index 2482 is " + token);
To properly convert them into float[] for NDArray creation, use the following helper function:
/**
* Convert a List of Number to float array.
*
* @param list the list to be converted
* @return float array
*/
public static float[] toFloatArray(List<? extends Number> list) {
float[] ret = new float[list.size()];
int idx = 0;
for (Number n : list) {
ret[idx++] = n.floatValue();
}
return ret;
}
Now that you have everything you need, you can create an NDList and populate all of the inputs you formatted earlier. You're done with pre-processing!
Construct Translator¶
You need to do this processing within an implementation of the Translator interface. Translator is designed to do pre-processing and post-processing. You must define the input and output objects. It contains the following two override classes:
- public NDList processInput(TranslatorContext ctx, I)
- public String processOutput(TranslatorContext ctx, O)
Every translator takes in input and returns output in the form of generic objects. In this case, the translator takes input in the form of QAInput (I) and returns output as a String (O). QAInput is just an object that holds questions and answer; We have prepared the Input class for you.
Armed with the needed knowledge, you can write an implementation of the Translator interface. BertTranslator uses the code snippets explained previously to implement the processInputmethod. For more information, see NDManager.
manager.create(Number[] data, Shape)
manager.create(Number[] data)
The Shape for data0 and data1 is sequence_length. For data2 the Shape is just 1.
public class BertTranslator implements NoBatchifyTranslator<qainput, string=""> {
private List<string> tokens;
private Vocabulary vocabulary;
private BertTokenizer tokenizer;
@Override
public void prepare(TranslatorContext ctx) throws IOException {
URL path = Paths.get("build/mxnet/bertqa/vocab.json").toUri().toURL();
vocabulary =
DefaultVocabulary.builder()
.optMinFrequency(1)
.addFromCustomizedFile(path, VocabParser::parseToken)
.optUnknownToken("[UNK]")
.build();
tokenizer = new BertTokenizer();
}
@Override
public NDList processInput(TranslatorContext ctx, QAInput input) {
BertToken token =
tokenizer.encode(
input.getQuestion().toLowerCase(),
input.getParagraph().toLowerCase(),
384);
// get the encoded tokens that would be used in precessOutput
tokens = token.getTokens();
// map the tokens(String) to indices(long)
List<long> indices =
token.getTokens().stream().map(vocabulary::getIndex).collect(Collectors.toList());
float[] indexesFloat = toFloatArray(indices);
float[] types = toFloatArray(token.getTokenTypes());
int validLength = token.getValidLength();
NDManager manager = ctx.getNDManager();
NDArray data0 = manager.create(indexesFloat);
data0.setName("data0");
NDArray data1 = manager.create(types);
data1.setName("data1");
NDArray data2 = manager.create(new float[] {validLength});
data2.setName("data2");
return new NDList(data0, data1, data2);
}
@Override
public String processOutput(TranslatorContext ctx, NDList list) {
NDArray array = list.singletonOrThrow();
NDList output = array.split(2, 2);
// Get the formatted logits result
NDArray startLogits = output.get(0).reshape(new Shape(1, -1));
NDArray endLogits = output.get(1).reshape(new Shape(1, -1));
int startIdx = (int) startLogits.argMax(1).getLong();
int endIdx = (int) endLogits.argMax(1).getLong();
return tokens.subList(startIdx, endIdx + 1).toString();
}
}
Congrats! You have created your first Translator! We have pre-filled the processOutput() function to process the NDList and return it in a desired format. processInput() and processOutput() offer the flexibility to get the predictions from the model in any format you desire.
With the Translator implemented, you need to bring up the predictor that uses your Translator to start making predictions. You can find the usage for Predictor in the Predictor Javadoc. Create a translator and use the question and resourceDocument provided previously.
DownloadUtils.download("https://djl-ai.s3.amazonaws.com/mlrepo/model/nlp/question_answer/ai/djl/mxnet/bertqa/0.0.1/static_bert_qa-symbol.json", "build/mxnet/bertqa/bertqa-symbol.json", new ProgressBar());
DownloadUtils.download("https://djl-ai.s3.amazonaws.com/mlrepo/model/nlp/question_answer/ai/djl/mxnet/bertqa/0.0.1/static_bert_qa-0002.params.gz", "build/mxnet/bertqa/bertqa-0000.params", new ProgressBar());
BertTranslator translator = new BertTranslator();
Criteria<qainput, string=""> criteria = Criteria.builder()
.setTypes(QAInput.class, String.class)
.optModelPath(Paths.get("build/mxnet/bertqa/")) // Search for models in the build/mxnet/bert folder
.optTranslator(translator)
.optProgress(new ProgressBar()).build();
ZooModel model = criteria.loadModel();
String predictResult = null;
QAInput input = new QAInput(question, resourceDocument);
// Create a Predictor and use it to predict the output
try (Predictor<qainput, string=""> predictor = model.newPredictor(translator)) {
predictResult = predictor.predict(input);
}
System.out.println(question);
System.out.println(predictResult);
Based on the input, the following result will be shown:
[december, 2004]
That's it!
You can try with more questions and answers. Here are the samples:
Answer Material
The Normans (Norman: Nourmands; French: Normands; Latin: Normanni) were the people who in the 10th and 11th centuries gave their name to Normandy, a region in France. They were descended from Norse ("Norman" comes from "Norseman") raiders and pirates from Denmark, Iceland and Norway who, under their leader Rollo, agreed to swear fealty to King Charles III of West Francia. Through generations of assimilation and mixing with the native Frankish and Roman-Gaulish populations, their descendants would gradually merge with the Carolingian-based cultures of West Francia. The distinct cultural and ethnic identity of the Normans emerged initially in the first half of the 10th century, and it continued to evolve over the succeeding centuries.
Question
Q: When were the Normans in Normandy? A: 10th and 11th centuries
Q: In what country is Normandy located? A: france
For the full source code,see the DJL repo and translator implementation MXNet PyTorch.